C语言-共用体,枚举类型
枚举类型
共用体
位域
枚举类型
#include <stdio.h>
#define Mon 1
#define Tues 2
#define Wed 3
#define Thurs 4
#define Fri 5
#define Sat 6
#define Sun 7
int main(){
int day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}
我们可以用#define来给一些常量命名,但也有不少副作用,宏名过多,代码松散,看起来很臃肿,C语言提供了一种枚举(Enum)类型,能够列出所有可能的取值,并给他们一个名字。
枚举类型的定义形式为:
enum typeName{valueName1, valueName2,valueName3,…………};
enum是一个新的关键字,专门用来定义枚举类型,这也是它在C语言中的唯一用途;typeName是枚举类型名字;valueName1, valueName2, valueName3, …………是每个值对应的名字的列表。注意最后的;不能少。
#include <stdio.h>
int main(){
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun } day;
scanf("%d", &day);
switch(day){
case Mon: puts("Monday"); break;
case Tues: puts("Tuesday"); break;
case Wed: puts("Wednesday"); break;
case Thurs: puts("Thursday"); break;
case Fri: puts("Friday"); break;
case Sat: puts("Saturday"); break;
case Sun: puts("Sunday"); break;
default: puts("Error!");
}
return 0;
}
运行结果:
4↙
Thursday
用枚举类型实现上面的程序,这段程序的枚举类型有两种写法:
enum week{ Mon = 1, Tues, Wed, Thurs, Fri, Sat, Sun };
//或者
enum week{ Mon = 1, Tues = 2, Wed = 3, Thurs = 4, Fri = 5, Sat = 6, Sun = 7 };
这两种方式都能将其中的每一个名字都赋上值,第一种方法会从1开始递增,和第二种方法是等效的。
我们还可以定义枚举变量就类似于结构体变量命名方式。
我们在定义这些时需要注意两点:
- 枚举类型中的Mon、Tues、Wed 这些标识符的作用范围是全局的(严格来说是main()函数内部),所以说不能再定义与它们名字相同的变量。
- Mon、Tues、Wed 等都是常量,不能对它们进行赋值,只能将它们的值赋给其他变量。
枚举类型和宏非常相似,他们之间的区别就是,宏是在预处理阶段将名字替换成对应的值,枚举类型是在编译阶段将名字替换成对应的值,我们可以将枚举类型理解为编译阶段的宏。
Mon、Tues、Wed这些名字都被替换成了对应的数字。这意味着,Mon、Tues、Wed等都不是变量,它们不占用数据区的内存,而是直接被编译到命令里面,放到代码区,所以不能用&取它们的地址。
共用体
共用体的基本定义格式
union 共用体名{
成员列表
}
它和结构体是同样的用法,但是其中存在一些区别:结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。
union data{
int n;
char ch;
short m;
};
弄清成员之间究竟是如何相互影响的,就得了解各个成员在内存中的分布。以上面的 data 为例,各个成员在内存中的分布如下:
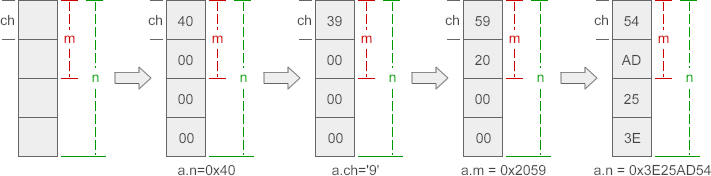 成员 n、ch、m 在内存中“对齐”到一头,对 ch 赋值修改的是前一个字节,对 m 赋值修改的是前两个字节,对 n 赋值修改的是全部字节。也就是说,ch、m 会影响到 n 的一部分数据,而 n 会影响到 ch、m 的全部数据。
成员 n、ch、m 在内存中“对齐”到一头,对 ch 赋值修改的是前一个字节,对 m 赋值修改的是前两个字节,对 n 赋值修改的是全部字节。也就是说,ch、m 会影响到 n 的一部分数据,而 n 会影响到 ch、m 的全部数据。
##共用体的应用 共用体在一般的编程中应用较少,在单片机中应用较多。对于 PC 机,经常使用到的一个实例是: 现有一张关于学生信息和教师信息的表格。学生信息包括姓名、编号、性别、职业、分数,教师的信息包括姓名、编号、性别、职业、教学科目。请看下面的表格:
| Name | Num | Sex | Profession | Score / Course |
|---|---|---|---|---|
| HanXiaoXiao | 501 | f | s | 89.5 |
| YanWeiMin | 1011 | m | t | math |
| LiuZhenTao | 109 | f | t | English |
| ZhaoFeiYan | 982 | m | s | 95.0 |
f 和 m 分别表示女性和男性,s 表示学生,t 表示教师。可以看出,学生和教师所包含的数据是不同的。现在要求把这些信息放在同一个表格中,并设计程序输入人员信息然后输出。
如果把每个人的信息都看作一个结构体变量的话,那么教师和学生的前 4 个成员变量是一样的,第 5 个成员变量可能是 score 或者 course。当第 4 个成员变量的值是 s 的时候,第 5 个成员变量就是 score;当第 4 个成员变量的值是 t 的时候,第 5 个成员变量就是 course。
经过上面的分析,我们可以设计一个包含共用体的结构体,请看下面的代码:
#include <stdio.h>
#include <stdlib.h>
#define TOTAL 4 //人员总数
struct{
char name[20];
int num;
char sex;
char profession;
union{
float score;
char course[20];
} sc;
} bodys[TOTAL];
int main(){
int i;
//输入人员信息
for(i=0; i<TOTAL; i++){
printf("Input info: ");
scanf("%s %d %c %c", bodys[i].name, &(bodys[i].num), &(bodys[i].sex), &(bodys[i].profession));
if(bodys[i].profession == 's'){ //如果是学生
scanf("%f", &bodys[i].sc.score);
}else{ //如果是老师
scanf("%s", bodys[i].sc.course);
}
fflush(stdin);
}
//输出人员信息
printf("\nName\t\tNum\tSex\tProfession\tScore / Course\n");
for(i=0; i<TOTAL; i++){
if(bodys[i].profession == 's'){ //如果是学生
printf("%s\t%d\t%c\t%c\t\t%f\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.score);
}else{ //如果是老师
printf("%s\t%d\t%c\t%c\t\t%s\n", bodys[i].name, bodys[i].num, bodys[i].sex, bodys[i].profession, bodys[i].sc.course);
}
}
return 0;
}
运行结果:
Input info: HanXiaoXiao 501 f s 89.5↙
Input info: YanWeiMin 1011 m t math↙
Input info: LiuZhenTao 109 f t English↙
Input info: ZhaoFeiYan 982 m s 95.0↙
Name Num Sex Profession Score / Course
HanXiaoXiao 501 f s 89.500000
YanWeiMin 1011 m t math
LiuZhenTao 109 f t English
ZhaoFeiYan 982 m s 95.000000
位域
有些数据在存储时并不需要占用一个完整的字节,只需要几个二进制位即可,例如控制开关的0和1也就是用一个二进制位,正是这种情况,C语言提供了一种叫做位域的数据结构。
在结构体定义时,我们可以指定某个成员变量所占用的二进制位数,这就是位域。:
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
};
:后面的数字用来限定成员变量占用的位数。成员m没有限制,根据数据类型即可推算出它占用4个字节的内存。成员n、ch被:后面的数字限制,不能再根据数据类型计算长度。,他们分别占用4、6位内存。
#include <stdio.h>
int main(){
struct bs{
unsigned m;
unsigned n: 4;
unsigned char ch: 6;
} a = { 0xad, 0xE, '$'};
//第一次输出
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
//更改值后再次输出
a.m = 0xb8901c;
a.n = 0x2d;
a.ch = 'z';
printf("%#x, %#x, %c\n", a.m, a.n, a.ch);
return 0;
}
运行结果:
0xad, 0xe, $
0xb8901c, 0xd, :
对于 n 和 ch,第一次输出的数据是完整的,第二次输出的数据是残缺的。
第一次输出时,n、ch 的值分别是 0xE、0x24(’$’ 对应的 ASCII 码为 0x24),换算成二进制是 1110、10 0100,都没有超出限定的位数,能够正常输出。
第二次输出时,n、ch 的值变为 0x2d、0x7a(‘z’ 对应的 ASCII 码为 0x7a),换算成二进制分别是 10 1101、111 1010,都超出了限定的位数。超出部分被直接截去,剩下 1101、11 1010,换算成十六进制为 0xd、0x3a(0x3a 对应的字符是 :)。
C语言标准规定,位域的宽度不能超过他所依附的数据类型的长度。通俗的讲,成员变量都是有类型的,这个类型限制了成员变量的最大长度,:后面的数字不能超过这个长度。
例如上面的 bs,n 的类型是 unsigned int,长度为 4 个字节,共计 32 位,那么 n 后面的数字就不能超过 32;ch 的类型是 unsigned char,长度为 1 个字节,共计 8 位,那么 ch 后面的数字就不能超过 8。
我们可以这样认为,位域技术就是在成员变量所占用的内存中选出一部分位宽来存储数据。
C语言标准还规定,只有有限的几种数据类型可以用于位域。在 ANSI C 中,这几种数据类型是 int、signed int 和 unsigned int(int 默认就是 signed int);到了 C99,_Bool 也被支持了。
位域的存储
存储规则如下:
- 当相邻成员类型相同时,如果他们的位宽之和小于类型的sizeof大小,那么后面的成员紧邻前一个成员存储,直到不能容纳为止;如果他们的位宽之和大于类型的sizeof大小,那么后面的成员将从新的存储单元开始,其偏移量类型大小的整数倍。
#include <stdio.h>
int main(){
struct bs{
unsigned m: 6;
unsigned n: 12;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
return 0;
}
运行结果:4
m、n、p 的类型都是 unsigned int,sizeof 的结果为 4 个字节(Byte),也即 32 个位(Bit)。m、n、p 的位宽之和为 6+12+4 = 22,小于 32,所以它们会挨着存储,中间没有缝隙。
如果将成员 m 的位宽改为 22,那么输出结果将会是 8,因为 22+12 = 34,大于 32,n 会从新的位置开始存储,相对 m 的偏移量是 sizeof(unsigned int),也即 4 个字节。
如果再将成员 p 的位宽也改为 22,那么输出结果将会是 12,三个成员都不会挨着存储。
- 当相邻成员的类型不同时,不同的编译器有不同的实现方案,GCC会压缩存储,而VC/VS不会。
#include <stdio.h>
int main(){
struct bs{
unsigned m: 12;
unsigned char ch: 4;
unsigned p: 4;
};
printf("%d\n", sizeof(struct bs));
return 0;
}
在 GCC 下的运行结果为 4,三个成员挨着存储;在 VC/VS 下的运行结果为 12,三个成员按照各自的类型存储(与不指定位宽时的存储方式相同)。
- 如果成员之间穿插着非位域成员,那么不会进行压缩。
struct bs{
unsigned m: 12;
unsigned ch;
unsigned p: 4;
};
在各个编译器下 sizeof 的结果都是 12。
通过上面的分析,我们发现位域成员往往不占用完整的字节,有时候也不处于字节的开头位置,因此使用&获取位域成员的地址是没有意义的,C语言也禁止这样做。地址是字节(Byte)的编号,而不是位(Bit)的编号。
无名位域
位域成员可以没有名称,只给出数据类型和位宽,如下所示:
struct bs{
int m: 12;
int : 20; //该位域成员不能使用
int n: 4;
};
无名位域一般用来作填充或者调整成员位置。因为没有名称,无名位域不能使用。
上面的例子中,如果没有位宽为 20 的无名成员,m、n 将会挨着存储,sizeof(struct bs) 的结果为 4;有了这 20 位作为填充,m、n 将分开存储,sizeof(struct bs) 的结果为 8。