C语言-变量和数据类型2
小数
英文字符
转义字符
标识符、关键字、注释、表达式、语句
加减乘除
自增自减
优先级和结合性
数据类型转换
小数
- 我们通常见到的小数一般都是
十进制形式。就是数学中的内种小数。 - 还有一种是
指数形式。例如:2.1E5 = 2.1 * 10^5;
C语言中的小数只有两种类型一种是float(单精度浮点型)和double(双精度浮点型)。
小数可以用printf输出,它们对应的格式控制符:
-
%f 以十进制输出float类型
-
%lf 以十进制输出double类型
-
%e 以指数形式输出float类型,输出结果中的e小写
-
%E 以指数形式输出float类型,输出结果中的E大写
-
%le 以指数形式输出double类型,输出结果中的e小写
-
%lE 以指数形式输出double类型,输出结果中的E大写
-
补充说明
%f和%lf默认保留六位小数,不足六位以0补齐,超过六位按四舍五入截断。- 将整数赋值给float变量时会变成小数。
- 以指数形式输出小数时,输出结果为科学计数法;也就是说,尾数部分的取值为:0<=尾数<10。
数字后缀
如果不想让数字使用默认的类型,那么可以给数字加上后缀,手动指明类型:
- 在整数后面紧跟
l或者L(不区分大小写)表明该数字是long类型 - 在小数后面紧跟
f或者F(不区分大小写)表明该数字是float类型
long a = 100l;
int b = 294;
short c = 32L;
float x = 52.55f;
double y = 18.6F;
float z = 0.02;
小数和整数相互赋值
- 将一个整数赋值给一个浮点数类型,在小数点后加0就可以了,加几个都无所谓
- 将一个小数赋值给整数类型,就得把小数部分丢掉,只能取整数部分,这会改变数字本来的值。注意是直接把小数部分丢掉,而不是四舍五入取近似值
字符
字符的表示
字符类型由单引号''包围,字符串由双引号""包围。
//正确的写法
char a = '1';
char b = '$';
char c = 'X';
char d = ' '; // 空格也是一个字符
//错误的写法
char x = '中'; //char 类型不能包含 ASCII 编码之外的字符
char y = 'A'; //A 是一个全角字符
char z = "t"; //字符类型应该由单引号包围
字符的输出
输出char类型的方法有两种:
- 使用专门的字符型输出函数 putchar
- 使用通过的格式化输出函数printf,char对应的格式控制符是%c
putchar函数每次只能输出一个字符,想要输出多次需要多次调用
字符与整数
我们知道,计算机在存储字符时并不是真的要存储字符实体,而是要存储该字符在字符集中的编号(也可以叫编码值)。对于char类型来说,它实际上存储的就是字符的ASCII码。
无论在哪个字符集中,字符编号都是一个整数;从这角度考虑,字符类型和整数类型本质上没有区别。
我们可以给字符型赋值一个整数,或者以整数的方式输出一个字符类型,反过来也是一样的。
可以说是ASCII码表将整数类型和字符类型关联了起来。
转义字符
转义字符以\或者\x开头,以\开头表示后跟八进制形式编码值,以\x开头表示后跟十六进制形式编码值。对于转义字符来说,只能使用八进制或者十六进制。
转义字符的初衷是用于ASCII编码,所以它的取值范围有限:
- 八进制形式的转义字符最多后跟三个数字,也即\ddd,最大值是\777
- 十六进制形式的转义字符最多后跟两个数字,也即\xdd,最大值是\x7f
超出范围的转义字符的行为是未定义的,有的编译器会将编码值直接输出,有的编译器则会报错。
对于ASCII编码,0~31(十进制)范围内的字符为控制字符,这种字符只能用转义字符的形式来表示,不过,直接记ASCII码不容易记住,所以针对常用的控制字符,C语言定义了简写方式:
| 转义字符 | 意义 | ASCII码值 |
|---|---|---|
\a |
响铃(BEL) | 007 |
\b |
退格(BS),将当前位置移到前一列 | 008 |
\f |
换页(FF),将当前位置移到下一页开头 | 012 |
\n |
换行(LF),将当前位置移到下一行开头 | 010 |
\r |
回车(CR),将当前位置移到本行开头 | 013 |
\t |
水平制表(HT) | 009 |
\v |
垂直制表(VT) | 011 |
\' |
单引号 | 039 |
\" |
双引号 | 034 |
\\ |
反斜杠 | 092 |
\n和\t是最常用的两个转义字符:
\n是用来换行的\t是用来占位的,一般相当于四个空格。
标识符、关键字、注释、表达式、语句
标识符
标识符就是程序员自己起的名字全部称之为标识符。
不过,名字也不能随便起,要遵守规范;C语言规定,标识符只能由字母数字下划线组成,并且第一个字符必须是字母或下划线,不能是数字。
使用标识符时还需要注意几点:
- C语言虽然不限制标识符长度,但是他收到不同编译器的限制,同时也受到操作系统的限制。例如在某个编译器中规定标识符前128位有效,当两个标识符前128位相同时,则被认为是同一个标识符。
- 在标识符中,大小写是有区别的。
- 标识符虽然由程序员随意定义,但标识符是用于标识某个量的符号,因此,命名应尽量有相应的意义,以便阅读理解。
- 我们定义的标识符不能和系统定义的关键字相同,否则会显示错误。
关键字
标准C语言中总共定义了32个关键字,也称保留字,例如:int、long、short、char、float等都是关键字。
注释
注释可以出现在代码中的任何位置,用来向用户阐述代码的含义。而在程序编译时会忽略注释。
- 单行注释以
//开头,直到本行末尾。 - 多行注释以
/*开头*/结尾,注释内容可以是一行也可以是多行。
表达式和语句
表达式和语句的概念在C语言中并没有明确的定义: - 表达式可以看作一个计算公式,往往由数值、变量、运算符等组成,表达式的结果必定是一个值。 - 语句的范围就更加广泛了,不一定计算,不一定有值,可以是某个操作,某个函数,选择结构,循环等。
加减乘除
在C语言中常用的数学运算符都是支持的。在C语言中,加号减号和数学是一样的,但是乘号和除号略有不同* /,另外C语言中还多了一个求余数的运算符%。
对除法的说明
C语言中除法运算很奇特,除数的不同也会导致运算结果的不同。
- 当除数和被除数都是整数时,运算结果也是整数;如果不能整除,那么就直接丢掉小数位,只保留整数部分。
- 一旦除数和被除数其中有一个为小数,则运算结果也是小数,并且是double类型的小数。
对取余运算的说明
取余运算只能为整数部分,也就是说取余符号两边都必须为整数,不然会报错,当然整数也包含负数,而针对负数,我们做一下特别说明。
- 如果%左边是正数,那么余数也是正数。
- 如果%左边是负数,那么余数也是负数。
运算符的简写
在运算符中我们可以在运算中这么写(我们假设用#号表示某种运算符):
a=a#b;
可以简写为:
a#=b;
#表示+、-、*、/、%中任一运算符。它只是一种简写形式并不会影响执行效率。
自增自减
在C语言中加一或者减一的操作可以从a=a+1或a+=1换成a++或++a。当然减一也是同样的方法,把+换成-就行了。
这种方式就叫做自增和自减。自增自减后将值在操作完成后将新值存入当前的变量中。
需要重点说明一下++放在前后的区别:
++放在前面叫做前自增。前自增先进行自增运算然后再进行其他操作。++放在后面叫做后自增。后自增先进行其他操作然后进行自增的运算。
自减也一样。
自增自减是很容易造成编写错误的,在自己编写程序时不建议使用这种方式。编译器不同它的编译过后的执行过程也将不同,会出现很多的UB行为,https://www.ddupan.top/posts/ub-in-strange-c-code 。
优先级和结合性
所谓优先级,就是当多个运算符出现在同一个表达式中时先执行哪个运算符
但是当优先级相同时我们又该如何,这时候就不得不提到结合性,先执行左边的就叫做左结合性,先执行右边就是右结合性。
具体的可以看另一篇文章""。
类型转换
自动类型转换
在不同类型混合运算时,编译器也会自动转换数据类型,将参与运算的所有数据转换成同一类型然后进行运算。
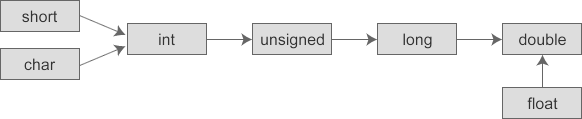
- 转换按数据长度增加的方向进行,以保证数值不失真,或者精度不降低。例如:int和long参与运算时,先把int类型的数据转换成long在运算。
- 所有浮点数运算都要转换成双精度浮点数来进行计算,即便运算中只有float类型
- char和short 参与运算时,必须转换成int类型。
下图对这种转换进行了形象的描述。
强制类型转换
如果有需要,程序员也可以自己在代码中明确地提出要进行的类型转换,这称为强制类型转换。
(新类型名称)表达式,例如:
(float) a; //将变量 a 转换为 float 类型
(int)(x+y); //把表达式 x+y 的结果转换为 int 整型
(float) 100; //将数值 100(默认为int类型)转换为 float 类型
强制类型转换会有一些失真的情况。
类型转换是临时性的
不管是自动类型转换还是强制类型转换,都只是为了本次运算而进行的临时性类型转换,转换的结果也会保存到临时的内存空间中,不会改变原有的数值类型或值